| 社区发现算法 | 您所在的位置:网站首页 › agm和e fb有什么区别 › 社区发现算法 |
社区发现算法
|
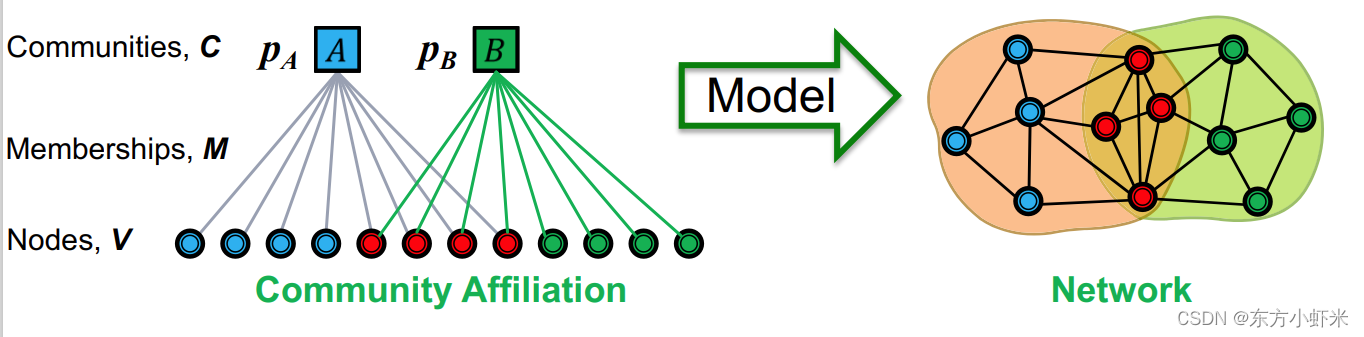
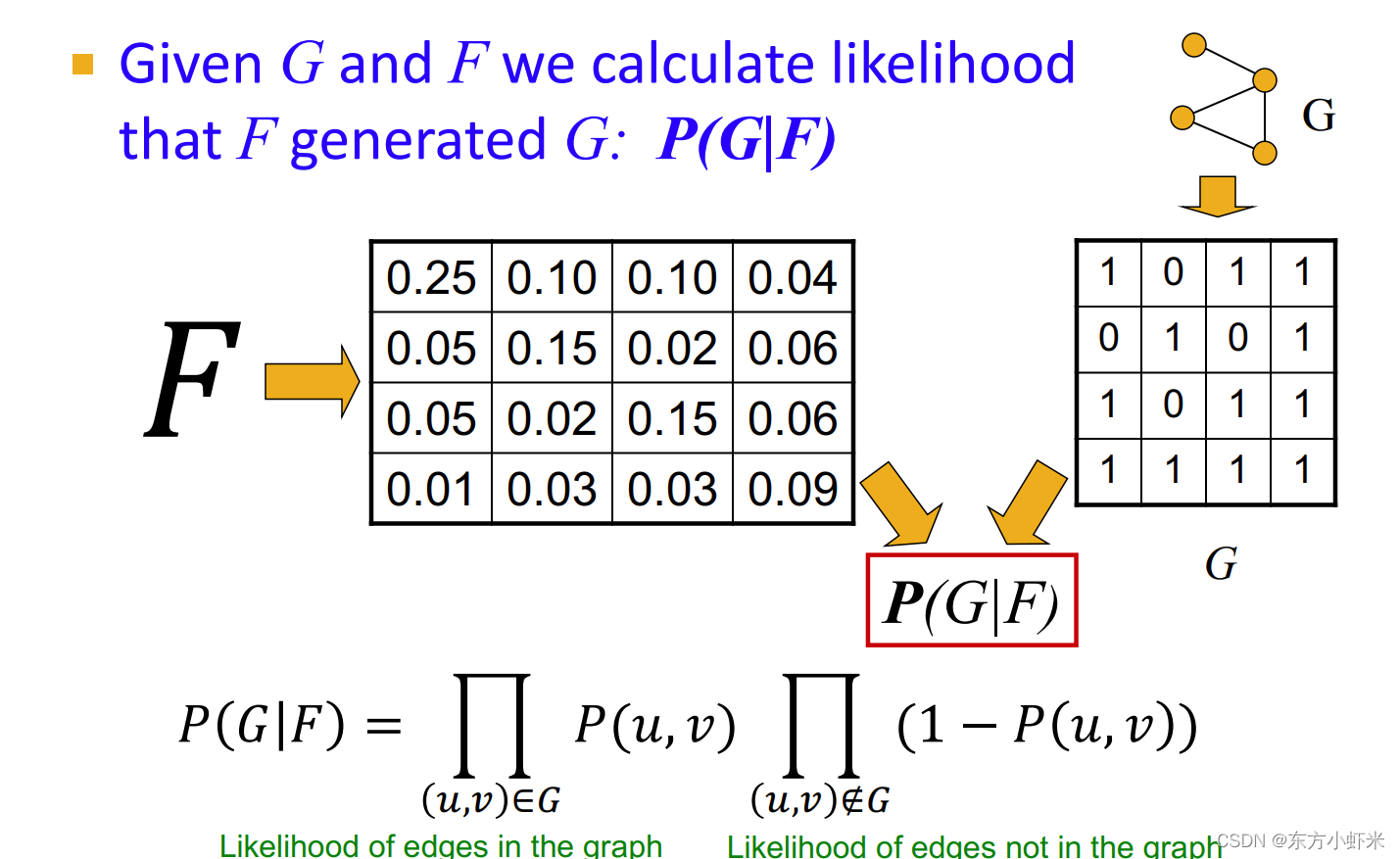
《Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach》 BIGCLAM(Cluster Affiliation Model for Big Networks,大型网络的聚类关系模型)是一个bipartite affiliation network模型。 BigCLAM方法流程: 第一步:定义一个基于节点-社区隶属关系生成图的模型(community affiliation graph model (AGM)) 第二步:给定图,假设其由AGM生成,找到最可能生成该图的AGM 通过这种方式,我们就能发现图中的社区。 community affiliation graph model (AGM) 《Community-affiliation graph model for overlapping network community detection》 通过节点-社区隶属关系(下图左图)生成相应的网络(下图右图)。 参数为节点 V,社区 C ,成员关系 M,每个社区 c 有个概率 p C p_C pC
AGM生成图的流程 给定参数 ( V , C , M , { p C } ) (V,C,M,\lbrace p_C\rbrace) (V,C,M,{pC}),每个社区 c 内的节点以概率 p C p_C pC互相链接。 对同属于多个社区的节点对,其相连概率就是: p ( u , v ) = 1 − ∏ c ∈ M u ⋂ M v ( 1 − p C ) p(u,v) = 1 - \prod_{c\in M_u \bigcap M_v}(1-p_C) p(u,v)=1−∏c∈Mu⋂Mv(1−pC) (注意:如果节点 u 和 v没有共同社区,其相连概率就是0。为解决这一问题,我们会设置一个 background “epsilon” 社区,每个节点都属于该社区,这样每个节点都有概率相连 p ( u , v ) = ϵ p(u,v) = \epsilon p(u,v)=ϵ 论文中建议 ϵ = 2 ∣ E ∣ ∣ V ∣ ( ∣ V ∣ − 1 ) \epsilon = \frac{2|E|}{|V|(|V|-1)} ϵ=∣V∣(∣V∣−1)2∣E∣) AGM可以生成稠密重叠的社区
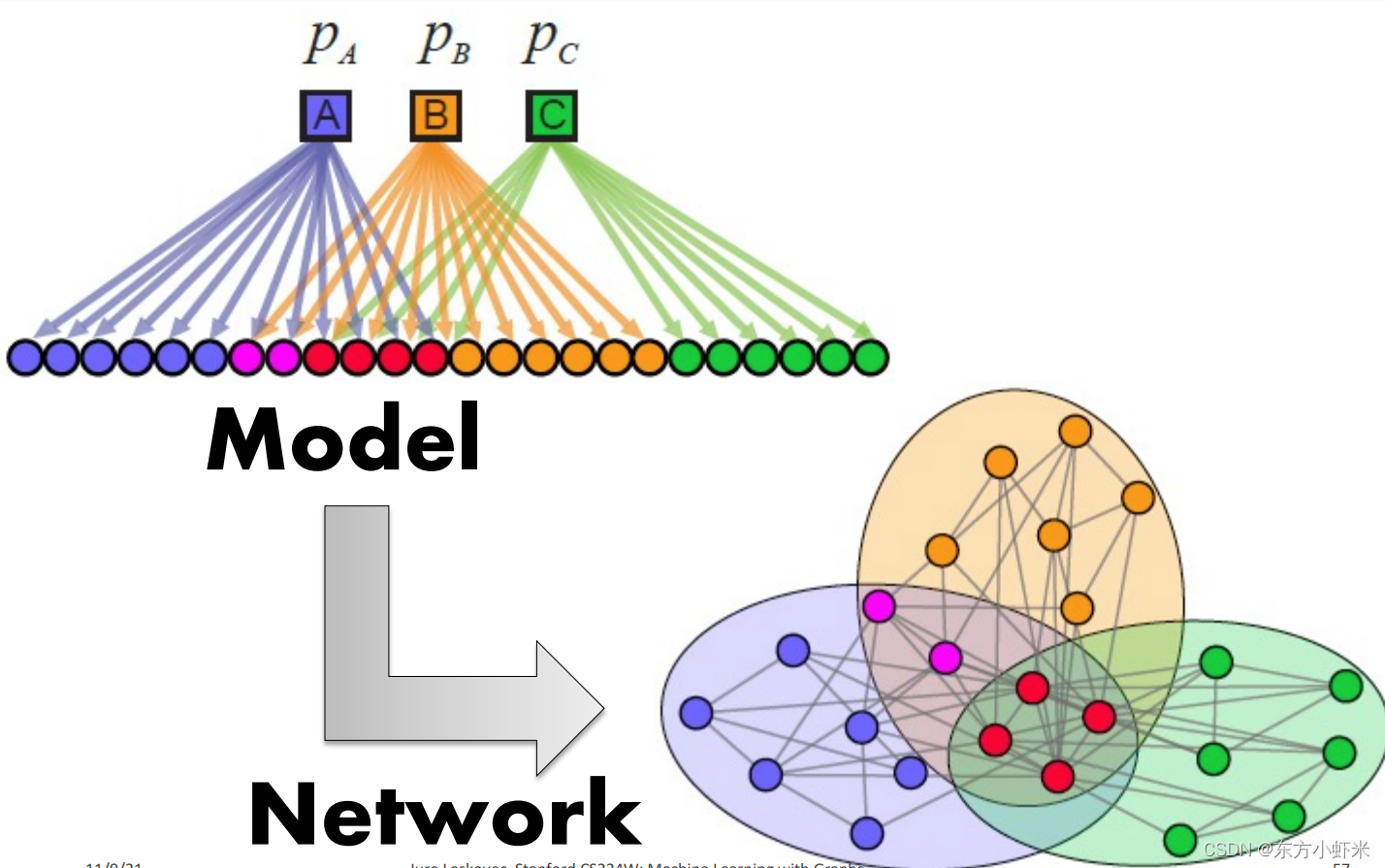
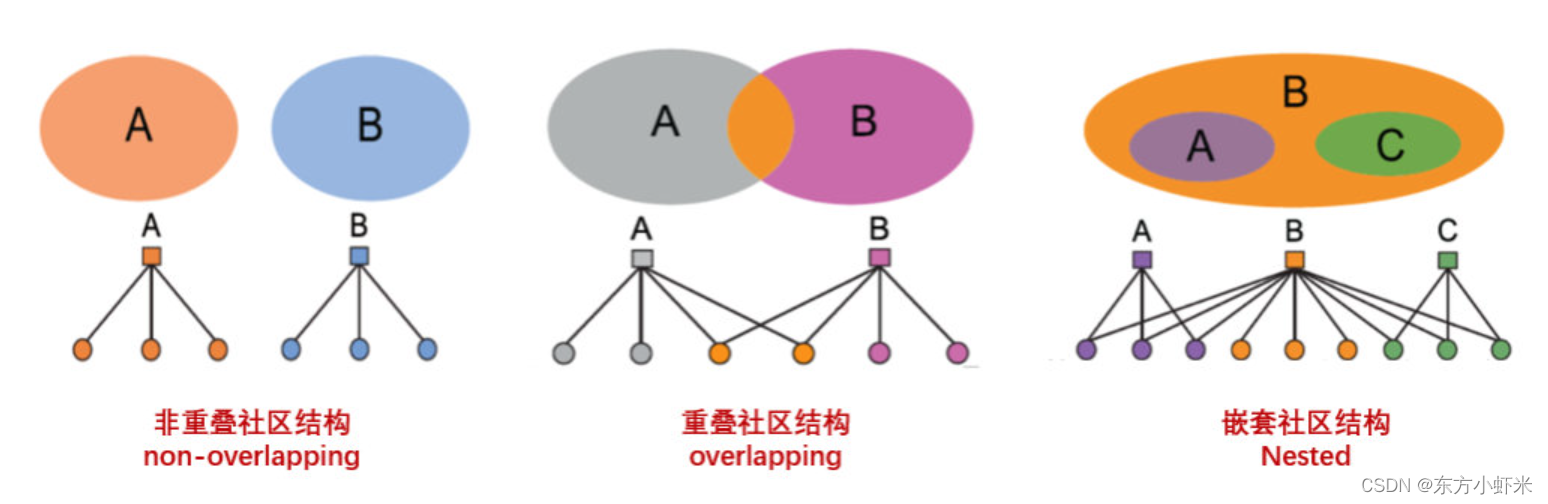
虽然,AMG模型是在重叠社区挖掘的时候引入的,但并不意味着AMG模型只能生成有重叠社区的网络。事实上,其非常灵活,可以生成不同类型的社区结构。如
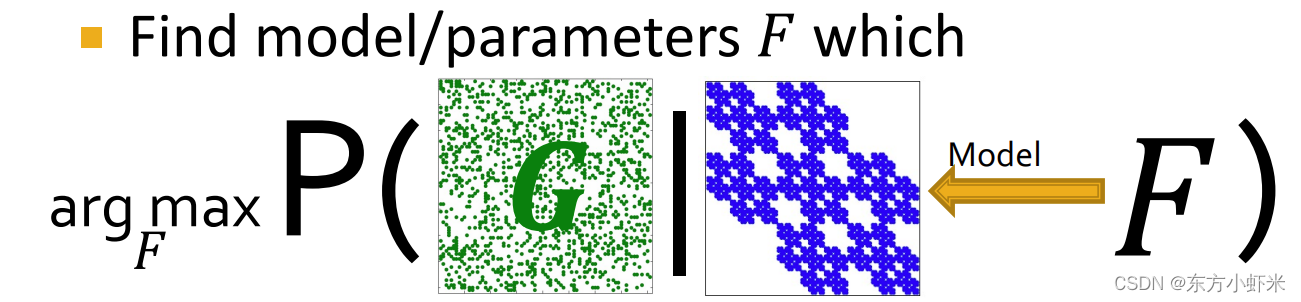
通过AGM发现社区:给定图,找到最可能产生出该图的AGM模型参数(最大似然估计) 图拟合(graph fitting) 通过前面我们知道AGM的参数主要有三个: 节点归属关系 𝑀社区内连接概率 p c p_c pc社区数 𝐶给定一张图G 我们需要找到 F = a r g m a x P ( G ∣ F ) F = argmax P(G|F) F=argmaxP(G∣F)
为了解决这一问题,我们需要高效的计算 P ( G ∣ F ) P(G|F) P(G∣F), 然后最大化F(使用梯度下降等优化算法) graph likelihood P ( G ∣ F ) P(G|F) P(G∣F) 通过F得到边产生的概率矩阵P(u,v), G具有邻接矩阵,从而得到 P ( G ∣ F ) = ∏ ( u , v ) ∈ G P ( u , v ) ∏ ( u , v ) ∉ G ( 1 − P ( u , v ) ) P(G|F) = \prod_{(u,v)\in G}P(u,v) \prod_{(u,v)\notin G}(1-P(u,v)) P(G∣F)=∏(u,v)∈GP(u,v)∏(u,v)∈/G(1−P(u,v)) 即通过AGM产生原图的概率。(原图中有的边乘以生成概率,没有的边乘以不生成的概率(1-生成概率))
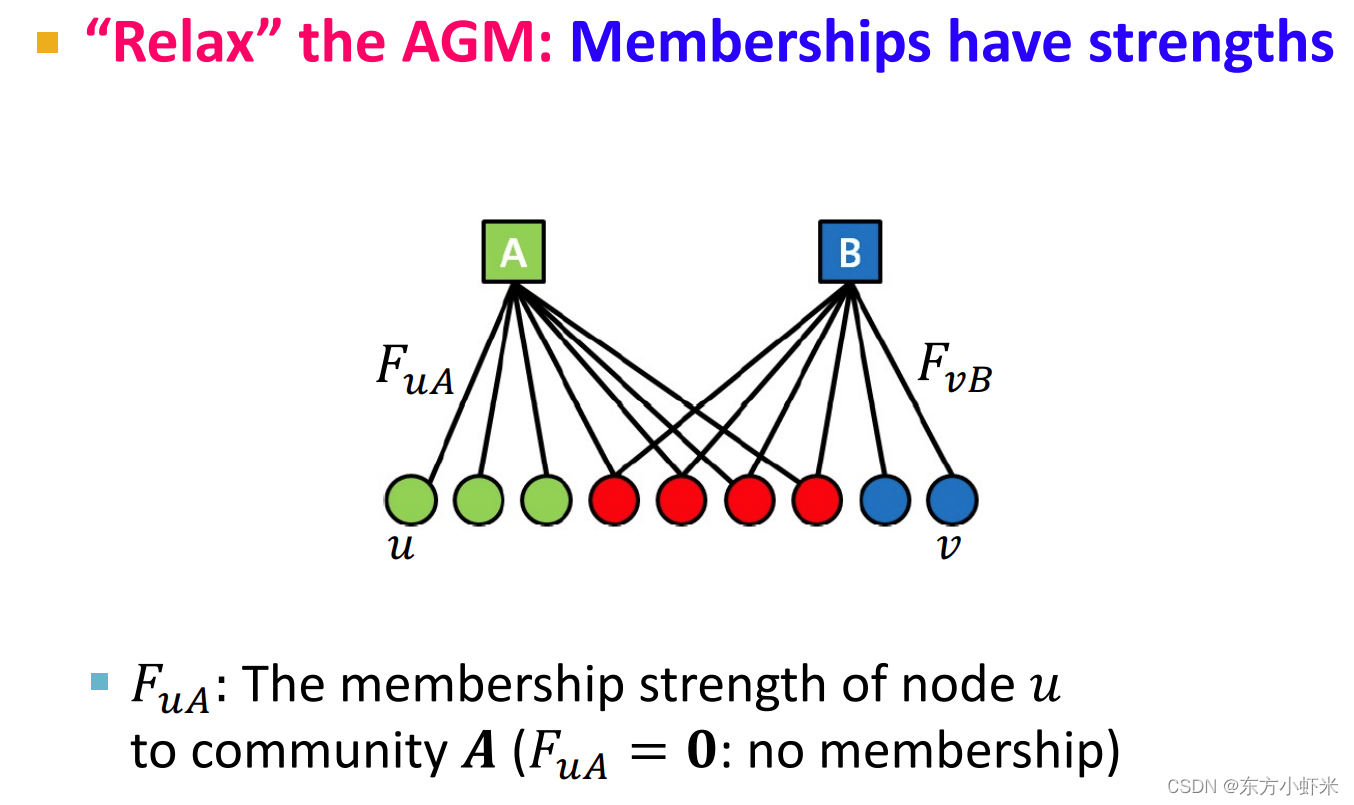
前面是普通的AGM。而BIGCLAM作为AGM的松弛版本,改进之处在于增加了边权重,采用了NMF方法等。 松弛AGM(“Relax” the AGM) 成员关系具有strength(如图所示): F u A F_uA FuA是节点 u属于社区 A 的成员关系的strength(如果 F u A = 0 F_uA = 0 FuA=0,说明没有成员关系(strength非负)
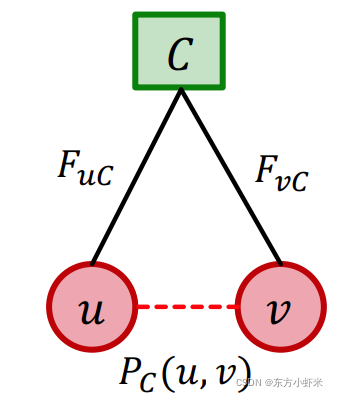
对于社区C,其内部节点u,v的链接概率为: P c ( u , v ) = 1 − e x p ( − F u C ⋅ F v C ) P_c(u,v) = 1 - exp(-F_uC \cdot F_vC) Pc(u,v)=1−exp(−FuC⋅FvC) 0 ≤ P c ( u , v ) ≤ 1 0\leq P_c(u,v)\leq1 0≤Pc(u,v)≤1
P c ( u , v ) = 0 P_c(u,v) = 0 Pc(u,v)=0(节点之间无链接) 当且仅当 F u C ⋅ F v C = 0 F_uC \cdot F_vC = 0 FuC⋅FvC=0(至少有一个节点对社区C没有成员关系) P c ( u , v ) ≈ 1 P_c(u,v) \approx 1 Pc(u,v)≈1(节点之间无链接) 当且仅当$F_uC \cdot F_vC $ 很大(两个节点都对社区C有强成员关系strength) 节点对之间可以通过多个社区相连,如果在至少一个社区中相连,节点对就相连,u,v至少在一个社区相连的概率为:
P ( u , v ) = 1 − ∏ C ∈ T ( 1 − P C ( u , v ) ) P(u,v) = 1 - \prod_{C\in T}(1-P_C(u,v)) P(u,v)=1−∏C∈T(1−PC(u,v)) 减数就是u与v在任何社区都不相连的概率
所以节点连接的概率与共享成员们的强度(两点同属于的社区数)成正比 P ( u , v ) = 1 − e x p ( − F u T F v ) P(u,v) = 1 - exp(-F_u^TF_v) P(u,v)=1−exp(−FuTFv) BigCLAM model 给定一个网络G(V,E), 我们最大化G在我们模型下的似然度
但是直接用概率的话,其值就是很多小概率相乘,数字小会导致numerically unstable的问题,所以要用log likelihood
优化$ l( F )$:从随机成员关系F开始,迭代直至收敛: 对每个节点u,固定其它节点的membership、更新 F u F_u Fu。我们使用梯度提升的方法,每次对 F u F_u Fu做微小修改,使log-likelihood提升。 对
F
u
F_u
Fu的偏微分等于: 在梯度提升时候,前部分与u的度数线性相关(快),后部分与图中节点数线性相关(慢) 因此我们可以将后者分解: 右式第一项可以提前计算并缓存好,每次直接用;后两项与u的度数线性相关。这样整个梯度步花费u的度数的线性时间。 总计来说,梯度步骤如下:
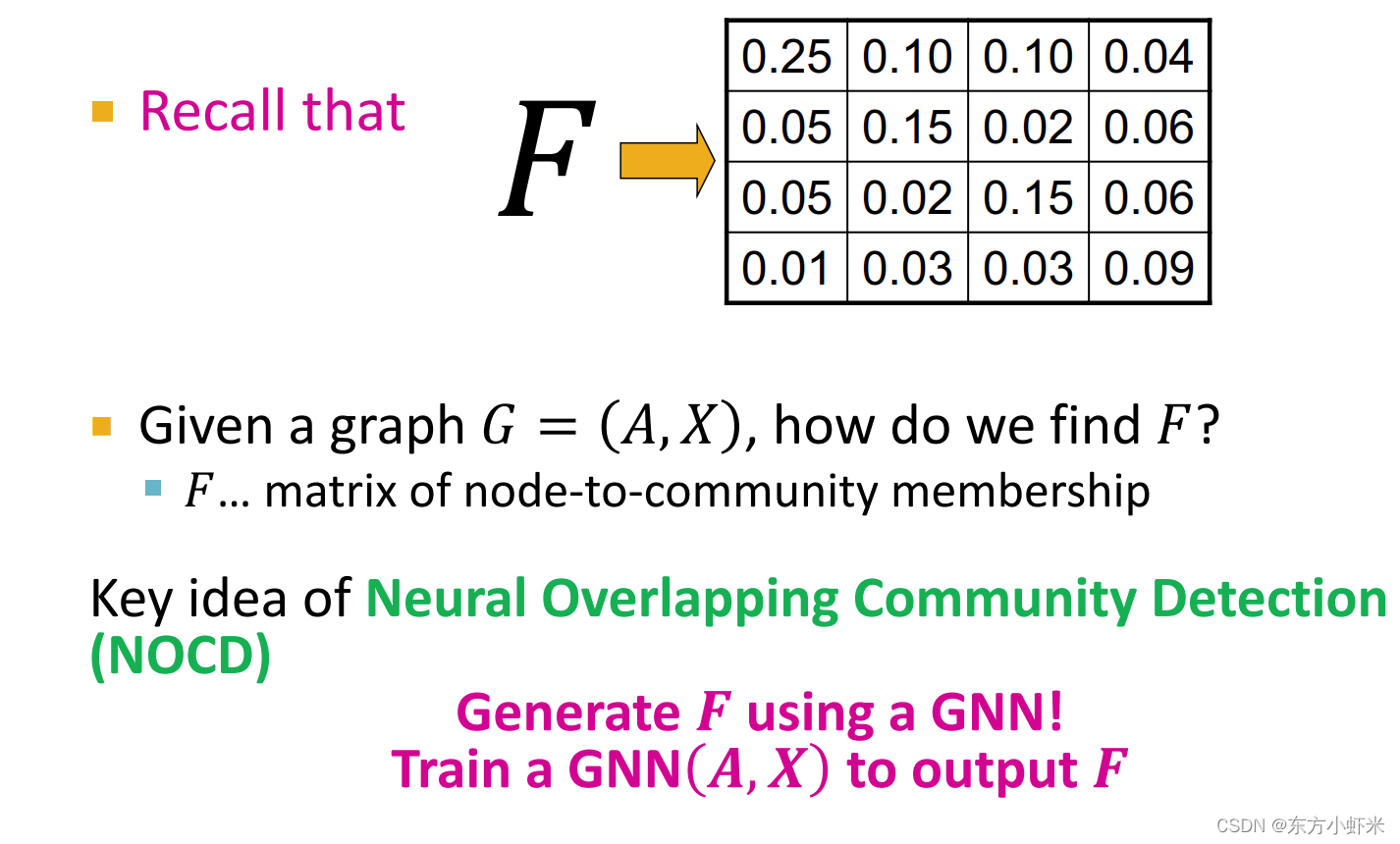
当我们找到了F,就可以生成想要的重叠社区,进而完成了我们的社区划分。 F还可以通过GNN获得
使用GNN的好处: GNN可以推广到其他图。否则,我们需要为每个新图优化𝐹GNN很好地利用了图结构——邻接矩阵𝑨和节点特征𝑿(例如:𝑋包括职业,爱好,教育在FB图上的用户。在对FB图进行训练后,GNN可能会从Instagram / Twitter推广到另一个社交网络。)
但是真实世界的图形通常是极其稀疏的, ∣ E ∣ n 2 < < 1 \frac{|E|}{n^2} |


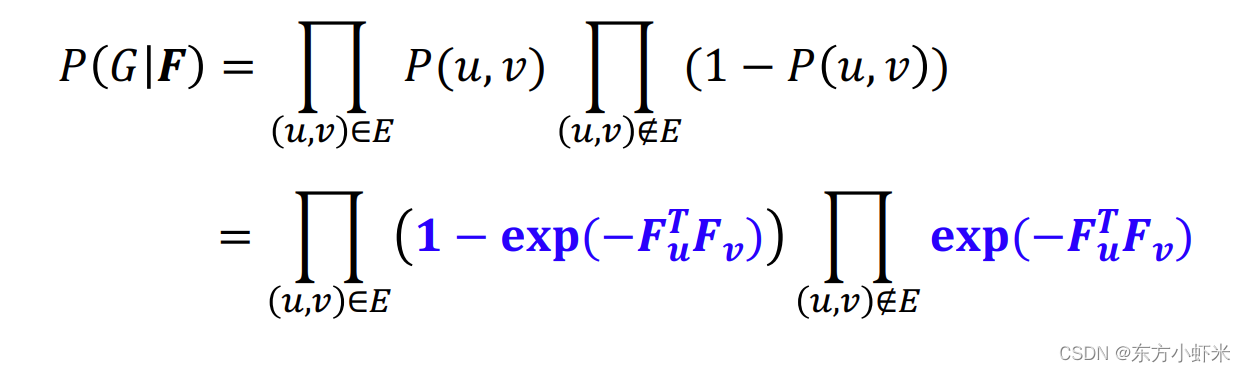


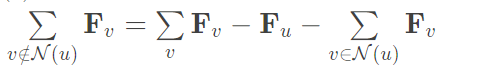


【本文地址】